问鼎赏金女王pg官网入口下载 xgboost实例_机器学习算法梳理—XGBOOST

CART树
算法分类与回归树英文称Classfication And Regression Tree,其缩写为CART。CART算法运用二分递归分割技术,此次技术用于把当次所涉样本集划分成两个具有差异的子样本集,借此让所生成的每一个并非直接属于末梢部分具有枝丫的节点都拥有两个不同走向的分支。并非处于末梢方位具有枝丫的节点所对应的特征取值分别是True以及False,其中向左方向伸展出的分支其取值为True,而向右方向伸展出的分支其取值为False,通过这样的情况可知CART算法所孕育出来的用于决策的树是那种在结构方面呈现出简洁特性的二叉树,。CART能够处理连续型变量与离散型变量,借助训练数据以递归方式划分特征空间来建树,通过验证数据实施剪枝,。
CART分类树
算法详解
CART分类树针对分类离散型数据进行预测,通过采用基尼指数来挑选最优特征,与此同时决定该特征的最优二值切分点。在分类过程中的假定时,存在K个类,样本点归属于第k个类的概率是Pk,也正是如此概率分布的基尼指数被定义为 ,。
按照基尼指数的定义,是能够得出样本集合D的基尼指数的。这里面的Ck,所代表的是数据集D当中属于第k类的样本子集 。
若数据集D依据特征A于某一取值a之上进行分割,进而得到D1、D2这两部分之后,那么于特征A之下集合D的基尼系数如下呈现。当中基尼系数Gini(D)用以表示集合D的不确定性,基尼系数Gini(D,A)表示在A=a分割之后集合D的不确定性。基尼指数越大,样本集合的不确定性便越大。
针对于属性A,分别去计算任意属性值把数据集划分成两部分之后的Gain_Gini,从中选取那其中的最小值,将此当做属性A所得到的最优二分方案。而后对于训练集S,计算全部属性的最优二分方案,从中选取那其中的最小值,把此作为样本及S的最优二分方案。

实例详解
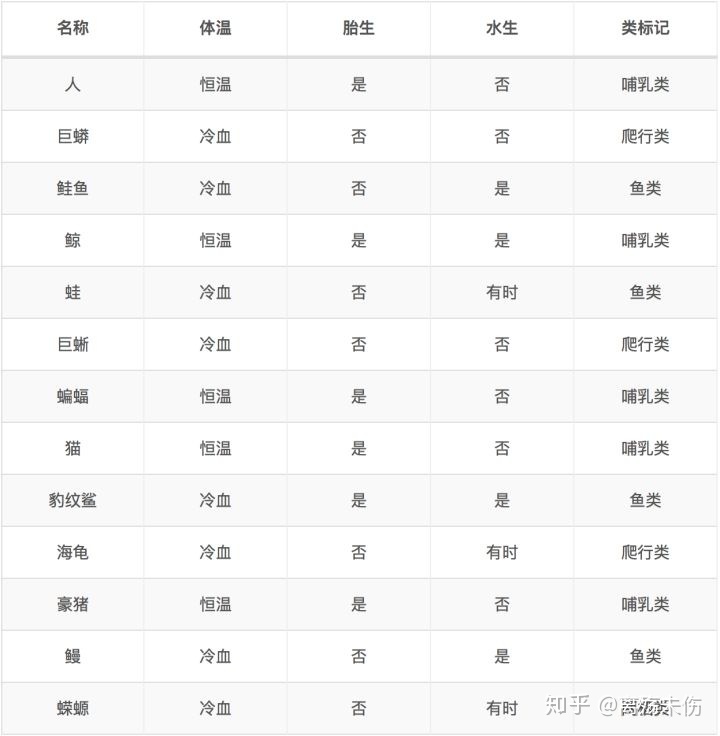
向着上述离散型数据,依照体温是恒温和非恒温来予以划分。这当中,处在恒温状态的时候涵盖哺乳类5个、鸟类2个,处于非恒温状态的时候涵盖爬行类3个、鱼类3个、两栖类2个,像下面所呈现的这样我们去计算D1,D2的基尼指数。
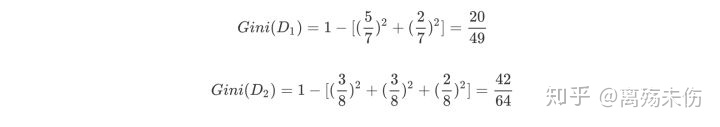
接下来,对特征体温下的数据集,进行计算,从而得出Gini指数,最终,我们挑选出Gain_Gini最小的特征以及与之对应的划分。
CART回归树
算法详解
CART回归树用于预测回归连续型数据呀,假设X是输入变量,Y是输出变量,并且Y属于连续变量范畴。在训练数据集所处的输入空间里面,采用递归方式,把每个区域划分成两个子区域,还要决定每个子区域上的输出值,以此构建二叉决策树。
对变量j实施遍历从而进行选择,针对规定切分变之j,去扫描切分点s,从中求取让特定式子得出最小值状态下的(j,s)这一对。这里规定,Rm代表受到划分的是输入空间,cm是该空间Rm所对应的固定输出值,是这么个情况 。
用选定的(j,s)对,划分区域并决定相应的输出值
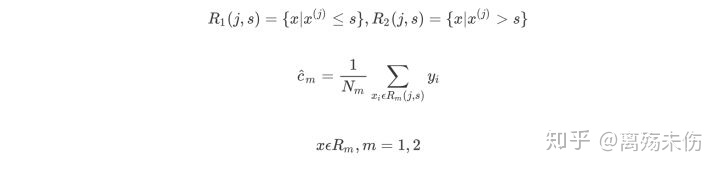
再度针对两个子区域施行上述步骤,将输入空间划分成M个区域,分别是R1,R2,…,Rm,进而生成决策树。
既然输入空间划分已然确定,那么就能够运用平方误差去表征回归树针对训练数据的预测方式,凭借平方误差最小的准则来求解每个单元之上的最优输出数值,是如此这般的情形。
实例详解

思考像上面所呈现的连续性变量,依据给定的数据点,思考在切分点为1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5、9.5的情况。针对各个切分点逐个地求出R1、R2、c1、c2以及m(s),举例来说,当切分点s等于1.5的时候,得到R1等于集合{1},R2等于集合{2,3,4,5,6,7,8,9,10},其中c1、c2、m(s)如下所展示的那样。
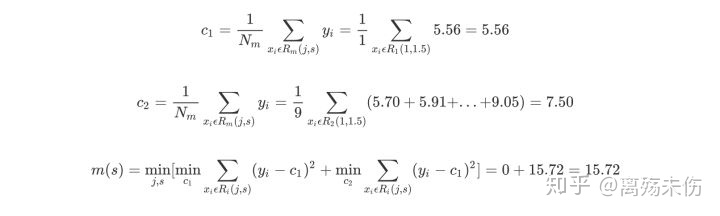
通过依次对(j,s)进行改变,能够得到s以及m(s)的计算结果,其所呈现的情况如下表所示 。

在x等于6.5这一时刻,这时R1呈现为包含1、2、3、4、5、6的集合,R2呈现为包含7、8、9、10的集合,c1的值是6.24,c2的值是8.9,回归树T1(x)是。
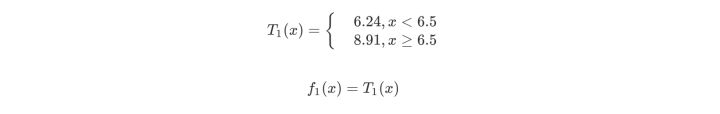
然后我们利用f1(x)拟合训练数据的残差,如下表所示

用f1(x)拟合训练数据得到平方误差
第二步去求T2(x),其 和求T1(x)的方法是一样的,只是用于拟合的数据并非别的,乃是上表所呈现的残差而已。这么做能够得到。
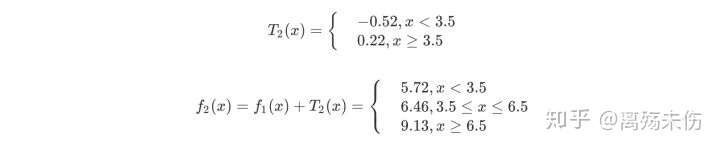
用f2(x)拟合训练数据的平方误差
接着去求取T3(x),然后再求取T4(x),之后又要去求取T5(x),最后还要去求取T6(x),情况如下所展示的那样 。

如下所示是用f6(x)拟合训练数据的平方损失误差,假设在这个时候已经达到了误差要求,那么f(x)=f6(x)就是所需求得的回归树 。
CART剪枝此处我们介绍代价复杂度剪枝算法
让我们把一棵已然充分生长的树称作T0 ,期望削减树的规模以避免过拟化,然而与此同时,当去除一些节点后,预测所产生的误差或许会增大,那么怎样去达成这两个变量之间的平衡便是问题的核心要点,所以我们运用一个变量α来进行平衡,进而定义损失函数如下 。
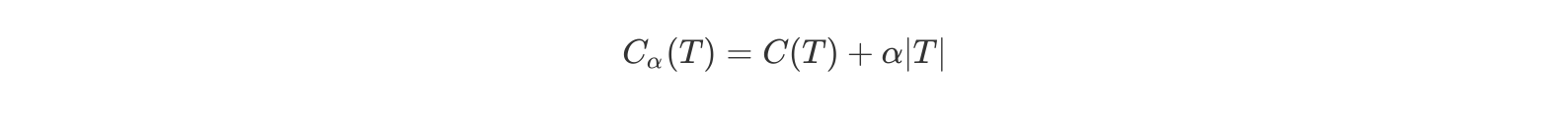
如此一来,我们要怎样去寻觅那个恰当的α,进而让拟合程度与复杂度之间达成最佳的平衡呢,确切的办法便是把α从0取值直至正无穷,针对每一个固定不变的α,我们都能够找到致使Cα(T)为最小的最优子树T(α) 。
α取值存在无限多的情况,然而T0的子树数量是有限的,Tn作为最后剩下来的根结点,子树的生成是依托前一个子树Ti,在剪掉某个内部节点之后,从而生成Ti+1,随后针对此类的子树序列分别运用测试集展开交叉验证,找出最优的那一个子树当作我们的决策树,子树序列呈现如下状 。
所以,CART剪枝包含两部分内容,其一为生成子树序列,其二是交叉验证,这里就不再做详尽的介绍了。
XGB原理
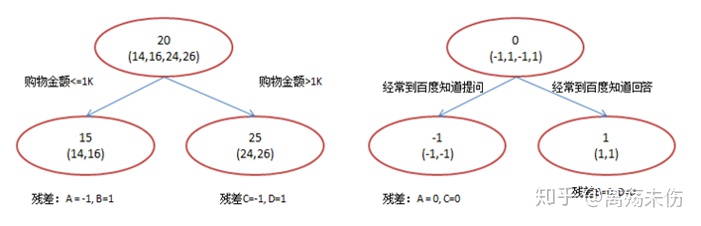
刚开始存在着一群样本巅峰国际pg平台官网,此时第一个节点的T等于1,那这个时候w是多少呢?并不知道它的值,它是需要求出来的,在这个时候所有样本的预测值都是w(决策树的节点代表着类别,回归树的节点代表着预测值)。要是这里使用平方误差来表示l(w−yi)误差,那么此函数便是一个针对w的二次函数,求取函数最小值的那个点就是这个节点的预测值。(借助泰勒展开来求最小损失函数)。
首先,对每一个特征去枚举其损失,接着从这些损失里选取最小值对应的那个feature当作分裂点,进而求出w1,随后开展下一个特征的枚举操作,再求出w2,如此这般,重复循环m步,这里所提到的yi就是y哦,也就是要对所有待分样本都去进行loss计算呢。
对于3......而言,能够求出全部的w,有人会提出疑问,何时停止计算呢?这与设置参数存在关联,像最大迭代次数,还有树的深度等等之类的。这一知识点相对而论也是比较繁杂众多的,后续关乎着往后再讲述针对优化方面会详尽细致地解说一番的了。
引申:
于第二步当中,在对每一个特征展开枚举从而求取损失之际,耗时程度颇为可观。随后,XGB对并行化予以了出色的支持 === 在挑选最佳分裂点之时,于执行枚举feature的操作过程里实施并行!
有一种算法即贪心算法,它等同于在某方面先进行剪枝操作,具体表现为,当引入的那种分裂所带来的增益小于一个设定的阀值之时,迭代过程便会停止。还有后剪枝,是于树构建完成之后再实施剪枝操作。
XGboost是于GBDT的基础之上,针对boosting算法所做的改进,其内部决策树运用的是回归树,下面对GBDT进行简要回顾:
于平方损失函数而言,回归树的分裂结点所拟合的乃是残差;对于一般损失函数(梯度下降)来讲,其拟合的却是残差的近似值,分裂结点进行划分之际,会枚举所有特征的值,进而选取划分点。
最后预测的结果是每棵树的预测结果相加。
xgboost算法原理知识
3.1 定义树的复杂度
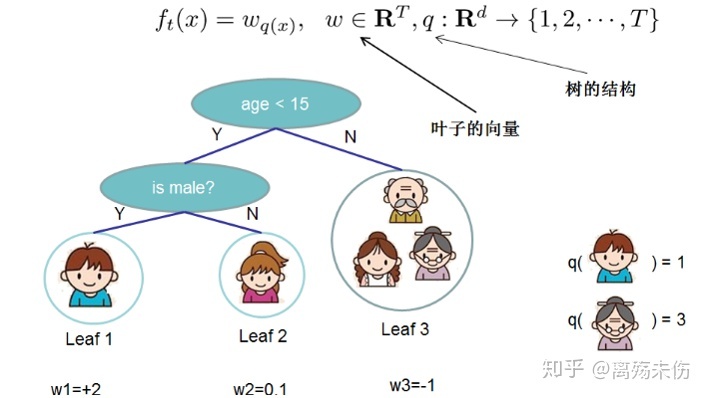
把树拆分成结构部分q和叶子权重部分w。
树的复杂度函数和样例:
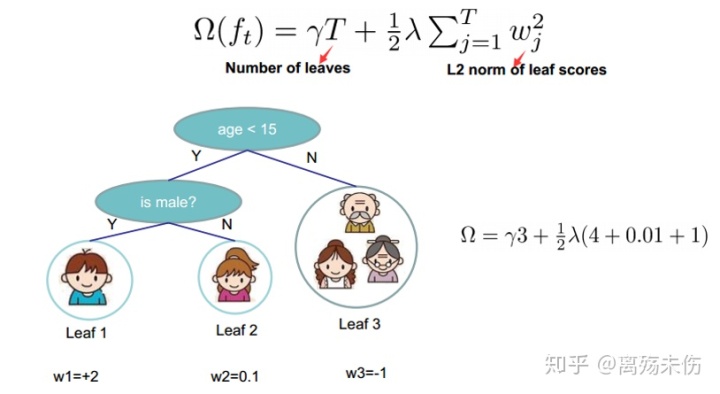
定义树的结构为那般,定义树的复杂度是何道理,其缘由简明扼要,如此为之便能去衡量模型的复杂度呀,进而能够有效地把控过拟合现象了呢。
xgboost中的boosting tree模型
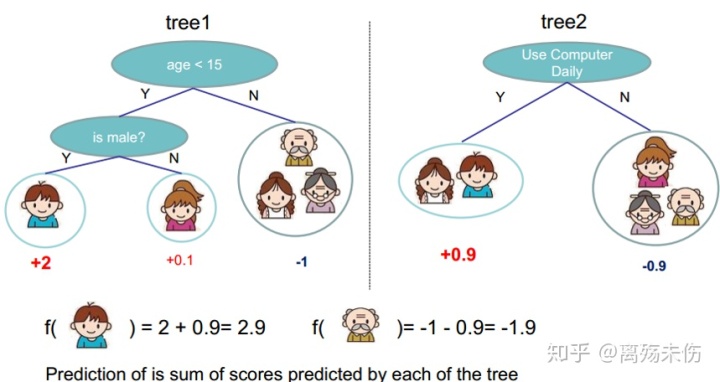
Xgboost 的提升模型,与传统的 boosting tree 模型相同,采用的皆是残差(或者梯度负方向),不一样之处在于,分裂结点进行选取之时,并一定非是最小平方损失 。
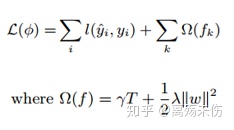
损失函数

目标函数的最终状态,仅仅依赖于,每个数据点,在误差函数方面,所具有的一阶导数,以及二阶导数。如此书写的缘由,十分明晰,鉴于在之前,目标函数求取最优解的进程当中,仅仅是针对平方损失函数,进行求解时较为便利,而针对其他的损失函数,求解过程会变得极为复杂,借助二阶泰勒展开式的变换方式,进而使得这类求解其他损失函数的操作,变得具备可行性了。相当不错!
在所定义的分裂候选集合形成之际,能够对目标函数作进一步的修改。分裂结点的候选响集属于非常关键的步骤,此为xgboost具备快速运行速度的保障,关于如何挑选出该集合,后续会给出介绍。
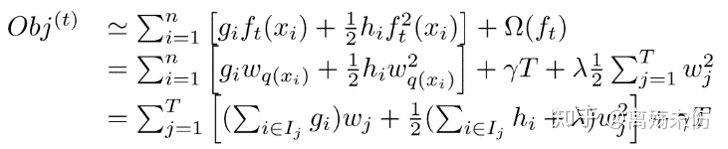
求解

分裂结点算法
3.1 基础精确的贪心算法
方程(7)的关键所在是寻得恰当的分割,精准的贪心算法借由罗列所有特征的可行划分来找出最优划分解,好多单机Tree算法运用此方式找到划分点,就像sklearn、Rs gbm、单机的XGBoost。精准的算法要排序成连贯的特征,随后计算每个可能划分的梯度统计值,如同算法1所示。

3.2 近似算法
我们通过精确列举所有可能的特征划分,这很耗时,在数据量很大时,几乎没办法把全部数据加载进内存,而且精确划分在分布式环境里也存在问题。我们总结出了近似策略,像算法二所展示的那样,算法先是依据特征分布的百分比来提议候选划分点,随后依照候选划分点把特征映射到槽中,进而找到最佳的划分百分点。全局划分要求特征划分要尽可能详细,局部划分初步便能达到要求 。有许多存在于分布式树中的近似算法会运用这个策略,还能够直接构造直方图近似,比如lightGBM直方图近似,其速度更快,不过好像准确度有所降低,另外也能够使用除分位法之外其他的策略,分位策略利于分布式实现,计算较为方便。

3.3 加权分位法
重要的步骤之一在于近似计算里提出候选的分位点,特征百分比常常作为分布式划分的依据。考虑多重集合时,key-value是第样本的那个(样本点的第K维特征,二阶导数),要定义排序函数。
表明比z小的点的那种比例,旨在去找出划分点,如此这般的划分点符合式子(9) 。
对于大数据而言,找到满足基准的划分点,具有重大意义,hi作为每个数据点的权重,通过这样尽量做到均匀划分,将方程(3)整理成平方差的形式,在此情形下,hi为label gi/hi的加权平方损失 。
在往昔用到的分位法里,并未将权值纳入考量范围,在诸多现存的近似方法当中,要么依据排序,要么借助启发式方法(此方法并无理论保障)实施划分,这篇文章作出的贡献乃是给出了具备理论保障的分布式加权分位法。
3.4 稀疏自适应分割策略
于实际运用当中,稀疏数据没法避免,致使稀疏数据的缘由主要涵盖:其一,数据存在缺失情况。其二,统计层面呈现为0 。其三,特征表示里的one - hot形式,过往经验显示,一旦出现稀疏以及缺失值时,算法得具备良好的稀疏自适应能力。

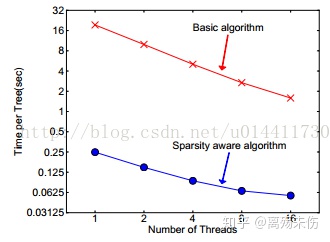
当特征值缺失出现之际,实例被映射至默认的方向分支,重点在于访问非缺失实体对Ik。当下算法将不存在的当作缺失值来处理,学到处理缺失的最优方向,算法借助枚举一致性情形同样适用于用户指定的值。现有的树系统仅优化稠密的数据,或者专注于处理有限的任务,比如分类编码。XGBoost以一种统一的方式处理所有的稀疏性情况。当稀疏情况出现之时,稀疏性计算仅有线性的计算复杂度。稀疏自适应算法,所呈现的情况是,它比基本的那些非稀疏数据算法要快上大约50倍,如图中所表示的那样。
正则化正则化目标函数
给出一个有着n个训练样本,m个features的既定数据集,即D=(xi,yi),在这里|D| = n,xi属于Rm,yi属于R,D=(xi,yi)同样满足|D| = n,xi属于Rm,yi属于R ,所采用的tree ensemble model运用了K次求和函数去预测给出结果:
yi^等于ϕ(xi),而ϕ(xi)等于从k等于1到K对fk(xi)进行求和,其中fk属于F,yi^等于ϕ(xi),而ϕ(xi)又等于从k等于1到K对fk(xi。
…… (1)
其中,F等于f(x),f(x)等于w乘以q(x),满足q是从Rm到T的映射,w属于RT,F等于f(x)www.pg.qq.com,f(x)等于w乘以q(x),满足q是从Rm到T的映射,w属于RT,这是回归树CART的空间。q表示每棵树的结构,能够把一个训练样本实例映射到相对应的叶子索引上。T是树中的叶子数。每个fk对应于一个独立的树结构q和叶子权重w。和决策树不一样的地方,是每棵回归树包含了在每个叶子上的一个连续分值 ,对此我们使用值wi来表示第i个叶子上的分值 。对于一个给定的样本实例,我们会运用树上由q给定的决策规则,把它归类到叶子上,接着,通过对相应叶子上由w给定的分值进行求和,来算出最终的预测值。为了在该模型里学到这些函数集合,我们会对下面的正则化目标函数执行最小化:
把这式子写成:L关于ϕ的表达式是,对i求和的l(yi^与yi的关系),再加上对i求和的Ω(fk),L关于ϕ的表达式是,对i求和的l(yi^与yi的关系),。
……(2)
其中,Ω(f)等于γT加上12λ乘以ω范数的平方,Ω(f)等于γT加上12λ乘以ω范数的平方 。
其中,ll是一个具备可微特性的凸loss函数,也就是所谓的differentiable convex loss function,它能够计算出预测值yi^与目标值yiyi之间的微分。第二项ΩΩ会对模型的复杂度施以惩罚。正则项能够针对最终所学到的权重予以平滑处理,以此避免出现overfitting的情况。与之相类似的正则化技术同样被应用于RGF模型,也就是正则贪婪树上。XGBoost的目标函数以及相应的学习算法相较于RGF而言更为简单,并且更易于实现并行化。正则参数被设置成0之际,目标函数等同于传统的gradient tree boosting方法呀。
对缺失值处理
平常状况下,我们人类处理缺失值之际,多数会选用中位数、均值或者二者的融合,以此对数值型特征予以填补,采用出现次数最为频繁的类别去填补缺失的类别特征。
挺多的机器学习算法没办法给出缺失值的自行处理,都得靠人去处理,然而 xgboost 模型是可以处理缺失值的,这也就是说模型是认同缺失值得以存在的。
本计划一开始是把原本那篇研讨论文里头涉及缺失值的那份处理方式,视作和稀疏矩阵的处理办法等同。在寻觅split point这个阶段,针对于那些特征呈现为missing的样本,并不会开展遍历统计,仅仅是侧重针对该列特征值为non - missing的那些样本对应的特征值实施遍历,依靠这样一种窍门从而降低了为稀疏离散特征去寻觅split point的那个时间方面的开销。在逻辑实现方面,为确保完备性,会分别处理两种情形,即把缺失该特征值的样本分配到左叶子结点的情形,以及将缺失该特征值的样本分配到右叶子结点的情形,计算增益后,选择增益大的方向进行分裂就行。能够为缺失值或者指定的值指定分支的默认方向,这可极大提升算法的效率。要是在训练中没有缺失值,而在预测中出现缺失,那么会自动把缺失值的划分方向放到右子树。

优缺点
xgboost的优势:
1、正则化
标准GBM的达成不存在如XGBoost这般的正则化举措。正则化对于削减过拟合而言同样具备助力作用。
事实上,XGBoost凭借“正则化提升(regularized boosting)”这项技术被众人所知 。
2、并行处理
XGBoost具备实现并行处理的能力 ,相较于GBM实现了速度上的显著飞跃 ,LightGBM是微软最新推出的一个在速度方面有提升的算法 ,XGBoost同样支持借助Hadoop来实现 。
3、高度的灵活性
XGBoost 允许用户定义自定义优化目标和评价标准 。
4、缺失值处理
XGBoost有着内置的处理缺失值的规则,用户要提供一个跟其它样本不一样的值,接着把这个值当作一个参数传进去,将此作为缺失值的取值,XGBoost在不同节点遇上缺失值时会采用不一样的处理方法,并且还会学习未来碰到缺失值时的处理方法。
5、剪枝
当处于分裂状态之际碰到一个负损失之时,GBM就会停止分裂,所以GBM实际上属于一个贪心算法,XGBoost会持续分裂直至指定的最大深度(max_depth),随后再回过头来进行剪枝,要是某个节点之后不再存在正值,那么它会将这个分裂去除 。
当一个呈现负数形式的损失(像是 -2 这样),在其后面跟着一个呈现正数形式的损失(例如 +10 这般)的时候,这种做法所具备的优点就会明显地展现出来。GBM 会在 -2 的这个位置停止下来,原因在于它碰到了一个负值。而 XGBoost 则会持续进行分裂,随后察觉到这两个分裂合并起来能够得到 +8pg国际电子游戏app,所以会保留这两个分裂。
6、内置交叉验证
XGBoost准许于每一回boosting循环里运用交叉验证,所以,能够便利地获取最佳boosting循环数量,。
而GBM使用网格搜索,只能检测有限个值。
7、在已有的模型基础上继续
XGBoost可以在上一轮的结果上继续训练。
在sklearn里的GBM的实现当中,同样是具备这个功能的,这两种算法,于这一点之上,是呈现出一致状况的。
缺点:发布时间短(2014),工业领域应用较少,待检验
应用场景
分类、回归
sklearn参数
可调整的参数数量众多的xgboost,具备着极大程度的自定义灵活性。举例而言 ,标点符号。
(1)objective
default=reg:linear
定义学习任务及相应的学习目标,可选的目标函数如下:
“reg:linear” –线性回归。
“reg:logistic” –逻辑回归。
其二分类的,归属逻辑回归范畴之类别问题,所输出的乃是概率这一项,以“binary:logistic”加以表述 。
“multi:softmax”,它用来处理多分类问题,并且在处理的时候,还需要去设置参数 num_class,也就是类别个数,呀。
(2)可用于评估的指标,其可供选择的项目被罗列于下方,此即评估指标:。
“rmse”,也就是均方根误差 ,称之为均方根误差 ,又称均方根误差 ,被叫做均方根误差 ,。
“logloss”,它指的是负对数似然,是一个特定的概念 。
(3)max_depth
default=6
数的最大深度。缺省值为6 ,取值范围为:

将参考资料称作小一,其中谈的是机器学习里的分类与回归树,其链接为zhuanlan.zhihu.com 。

把小毛驴,通俗易懂的,XGBoost算法入门,放在zhuanlan.zhihu.com上。
怎么处理xgboost缺失值的相关文段,位于https://blog.csdn.net/jasonzhangoo/article/details/73061060这个链接对应的网页上,此网页归属于blog.csdn.net;又有位于https://blog.csdn.net/a1b2c3d4123456/article/details/52849091网址对应的网页也在blog.csdn.net旗下里有相关内容;并且位于https://blog.csdn.net/u014411730/article/details/78796890链接对应的此网页所在网站同样是blog.csdn.net,而在www.jianshu.com上也有关于xgboost如何 handle missing values的内容 。

 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论